Showing 93 of 93on this page. Filters & sort apply to loaded results; URL updates for sharing.93 of 93 on this page
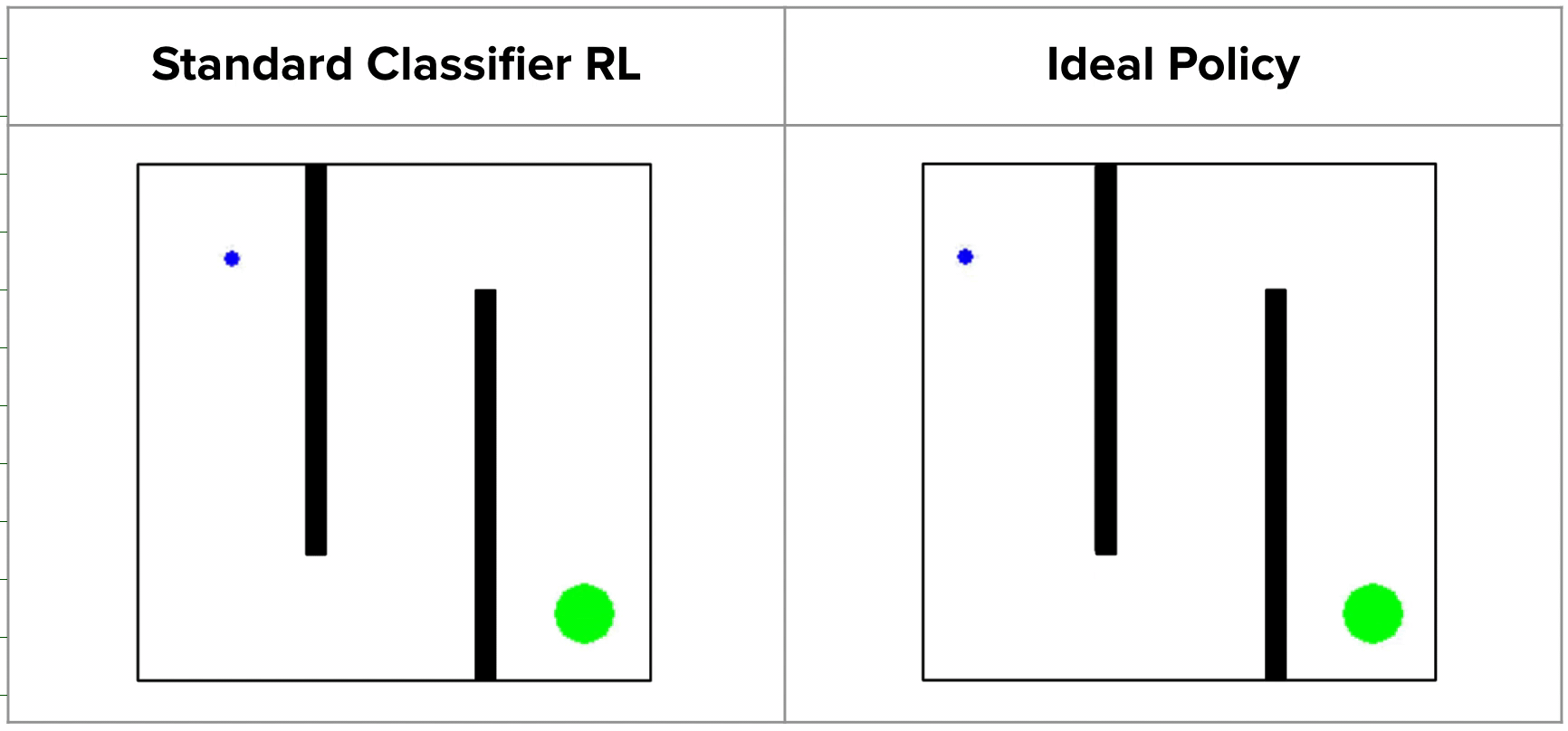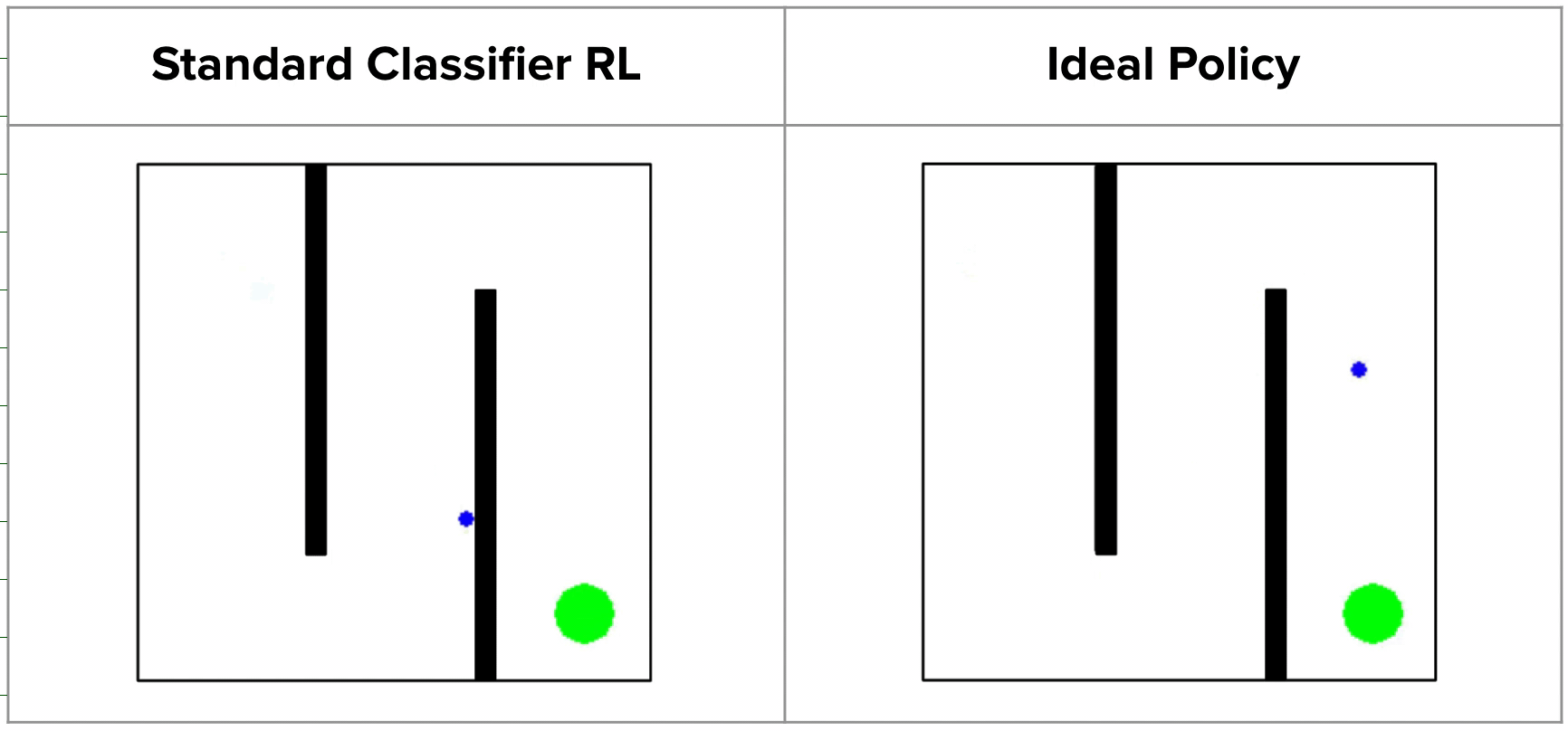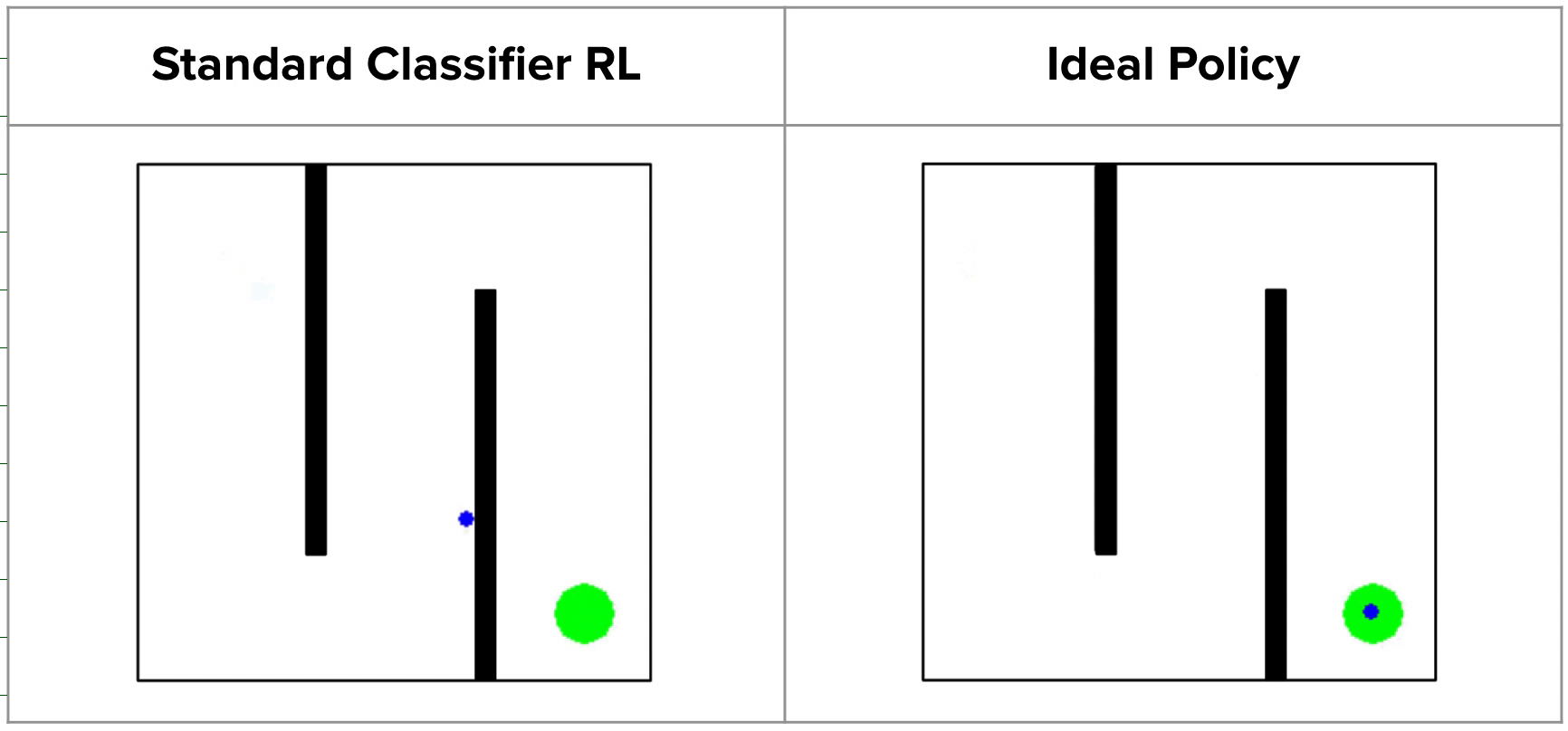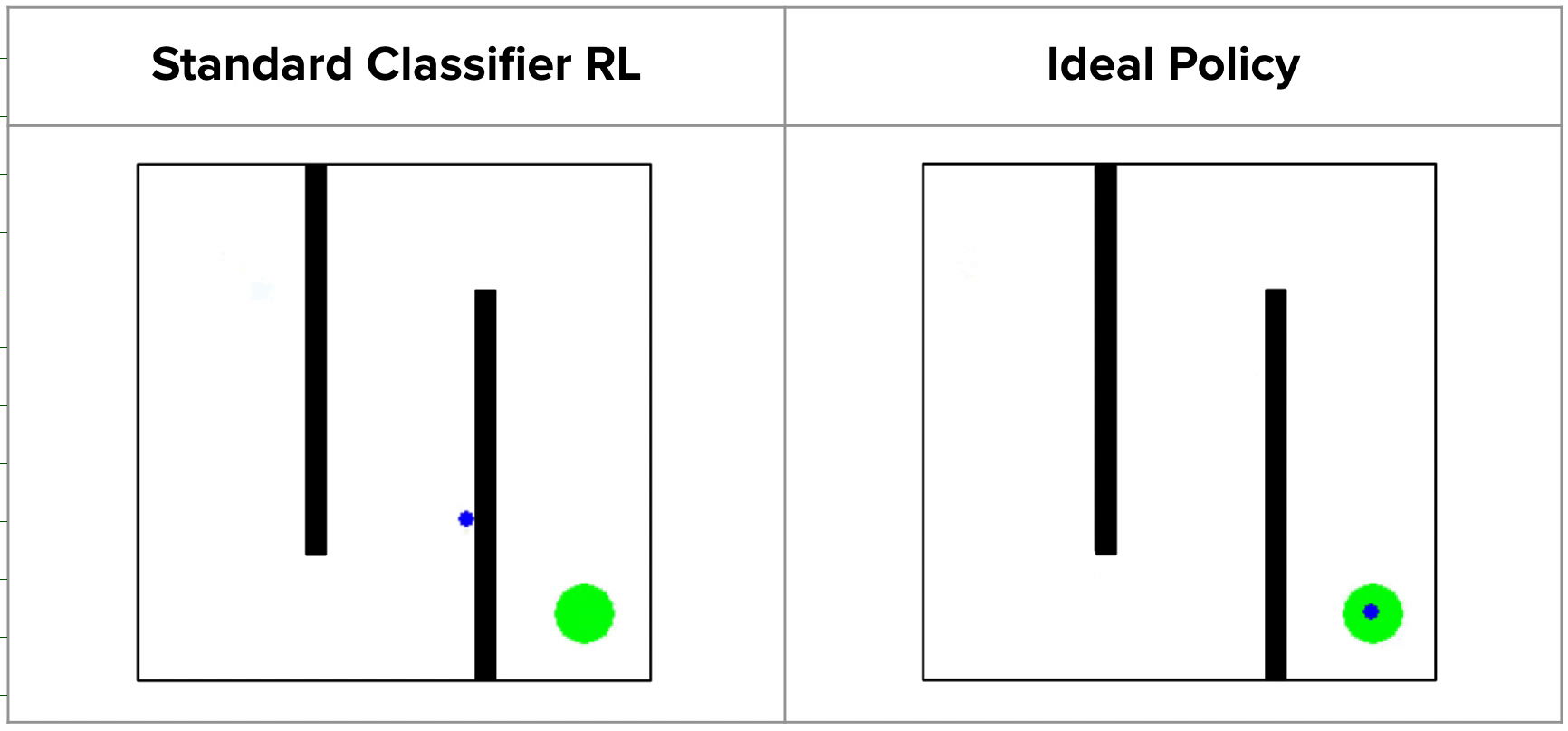
Inverse RL via State Marginal Matching (final project presentation for ...
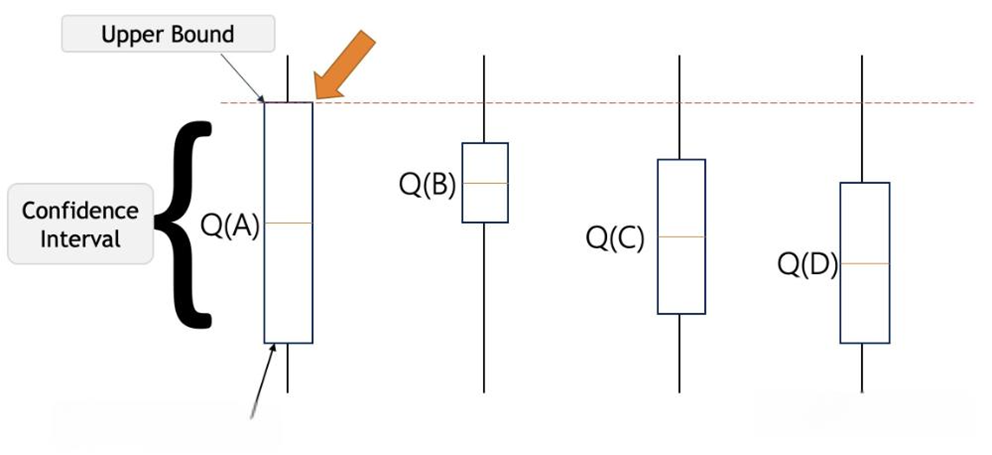
(a) A state marginal problem is asking whether, for a given set of ...
RL state transition diagram | Download Scientific Diagram
State variables of the RL agents. | Download Scientific Diagram
State Representation Learning for RL - Preferred Networks Research ...
State representation learning in RL context - 知乎
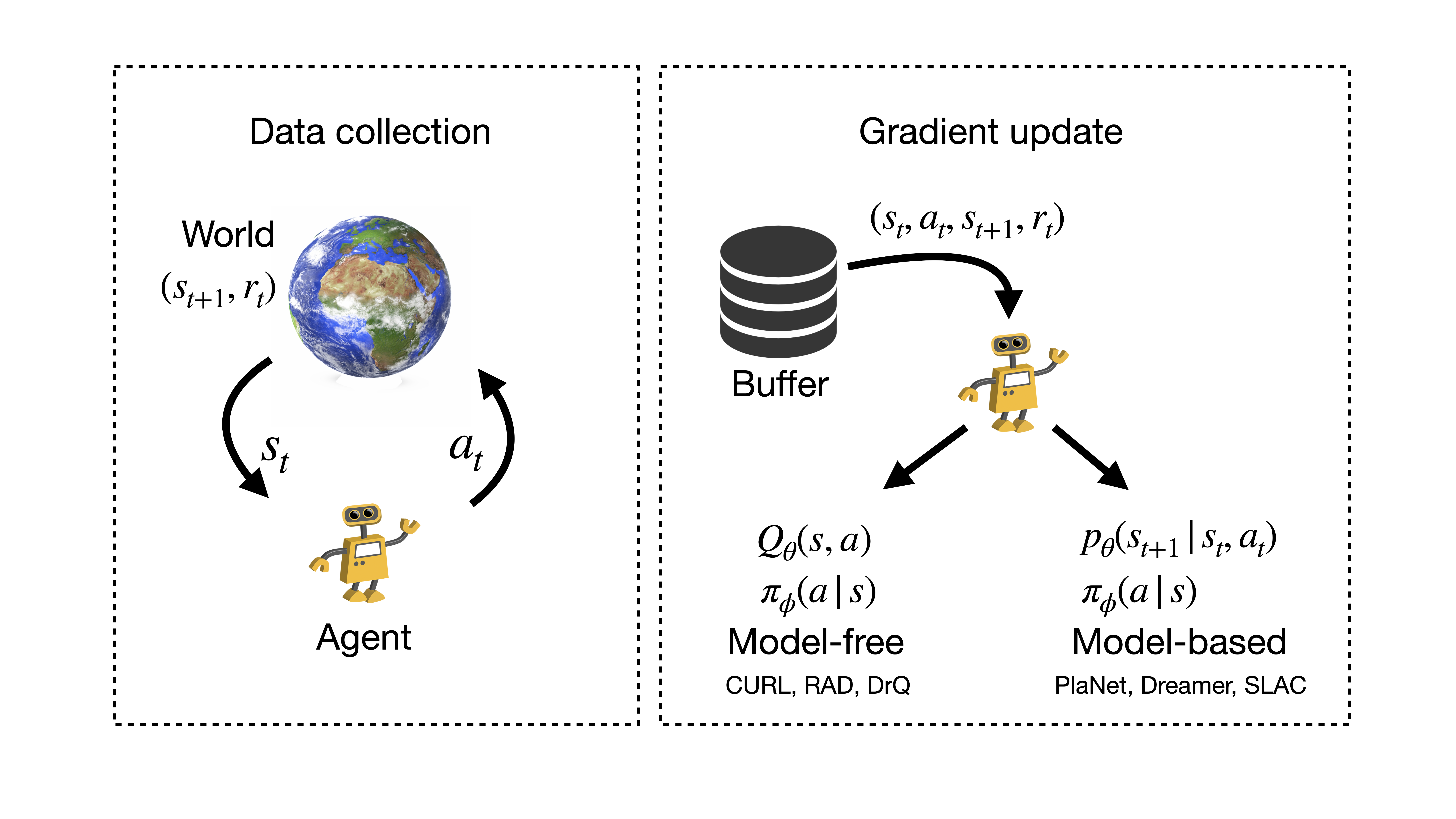
1: An overview of the RL framework. An agent in state s t takes action ...
Group-level marginal linear model analyses of resting state functional ...
Finding the estimate of the value of a state in RL agents — LessWrong
Different RL state representations for time-series built for being ...
Overall control and RL framework. A random initial state is fed into ...
Two state trajectories of RL agents during online implementation ...
| RL architecture: (A) classical online RL where state and reward are ...
1: Flow chart of state, control input and reward in the RL notation ...
Pictorial representation of RL framework constituting of agent ...
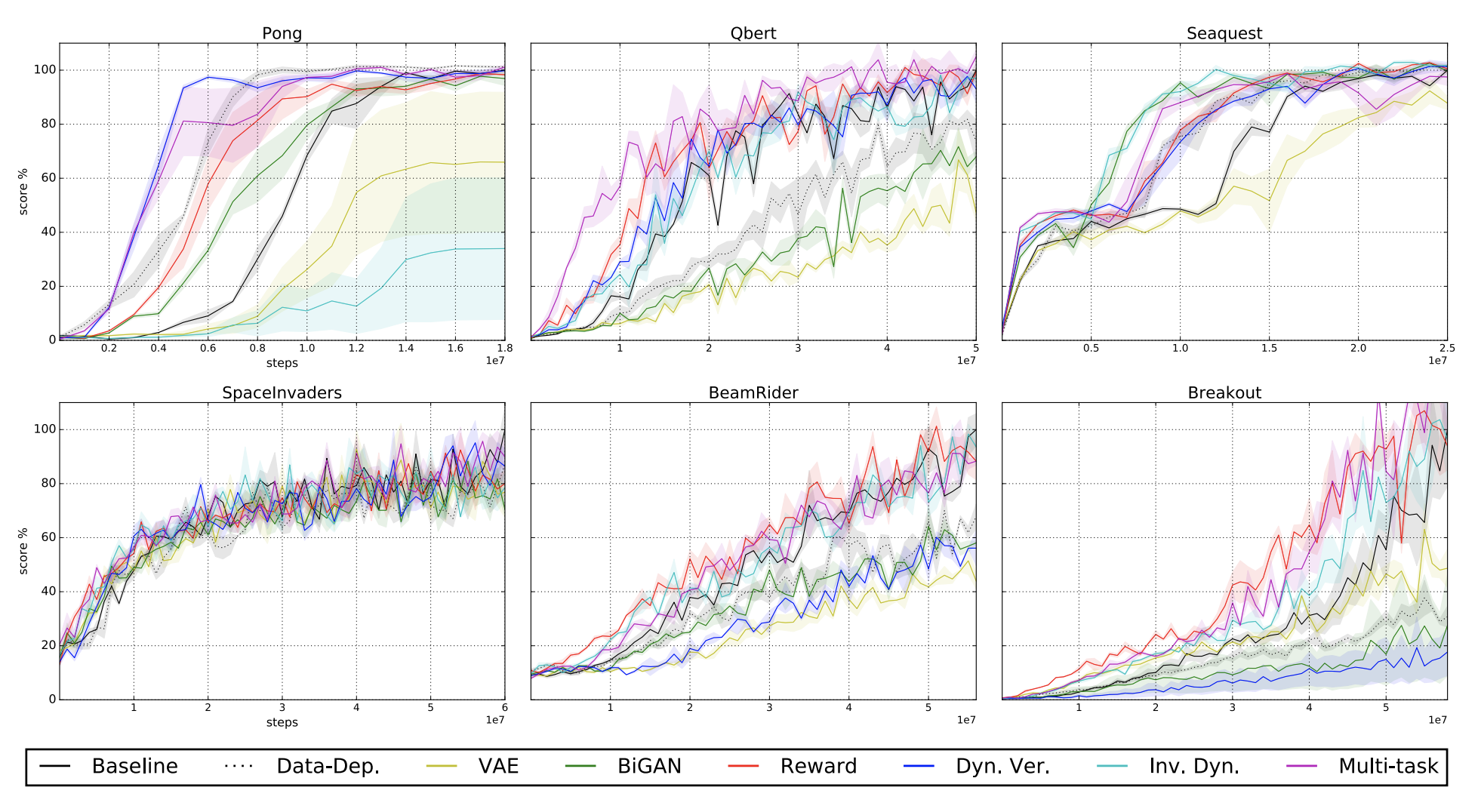
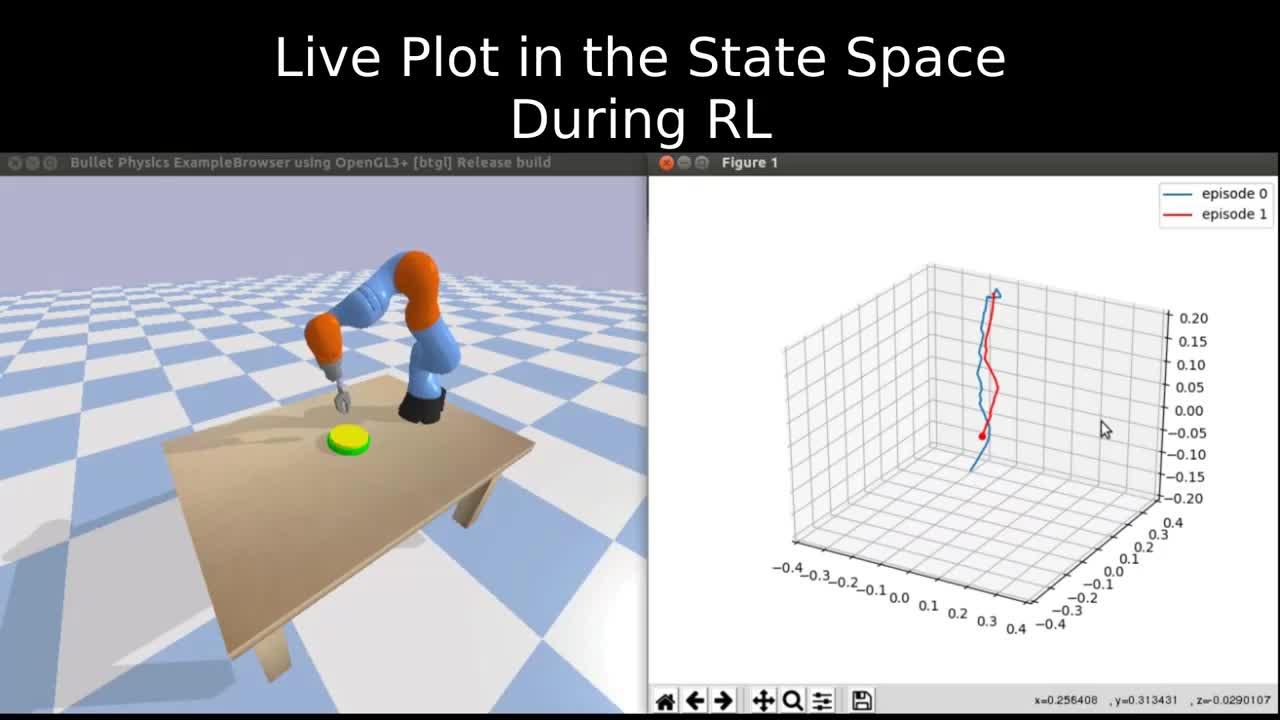
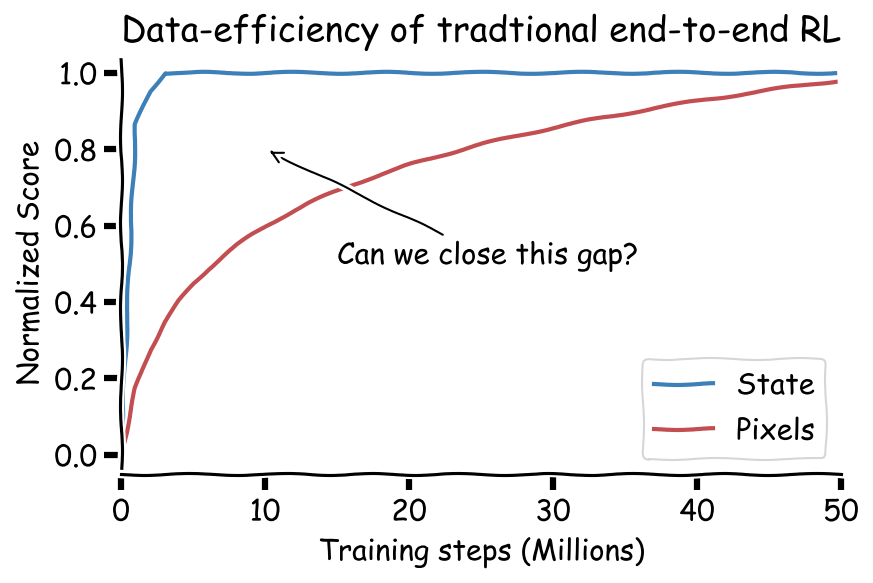
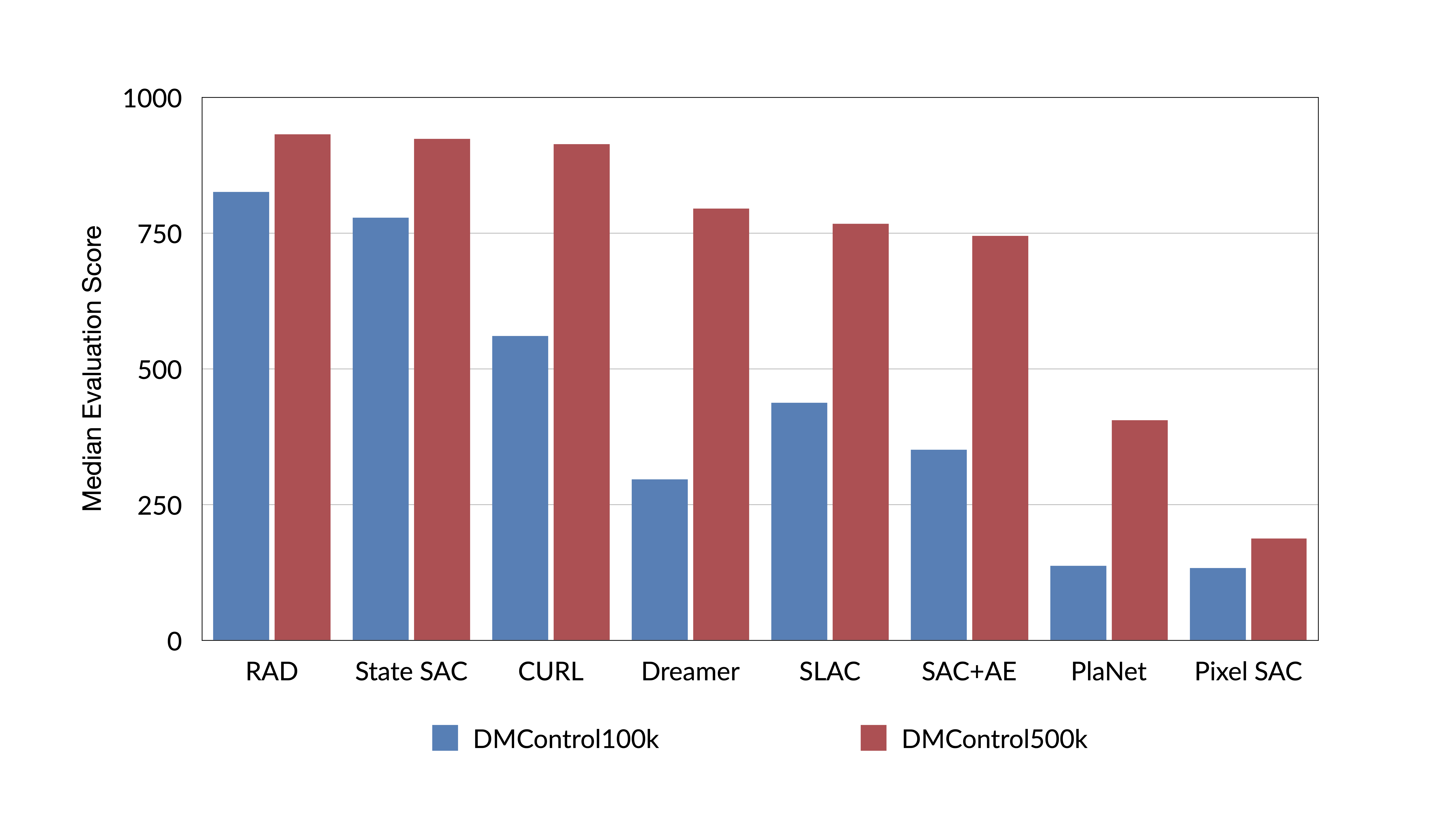
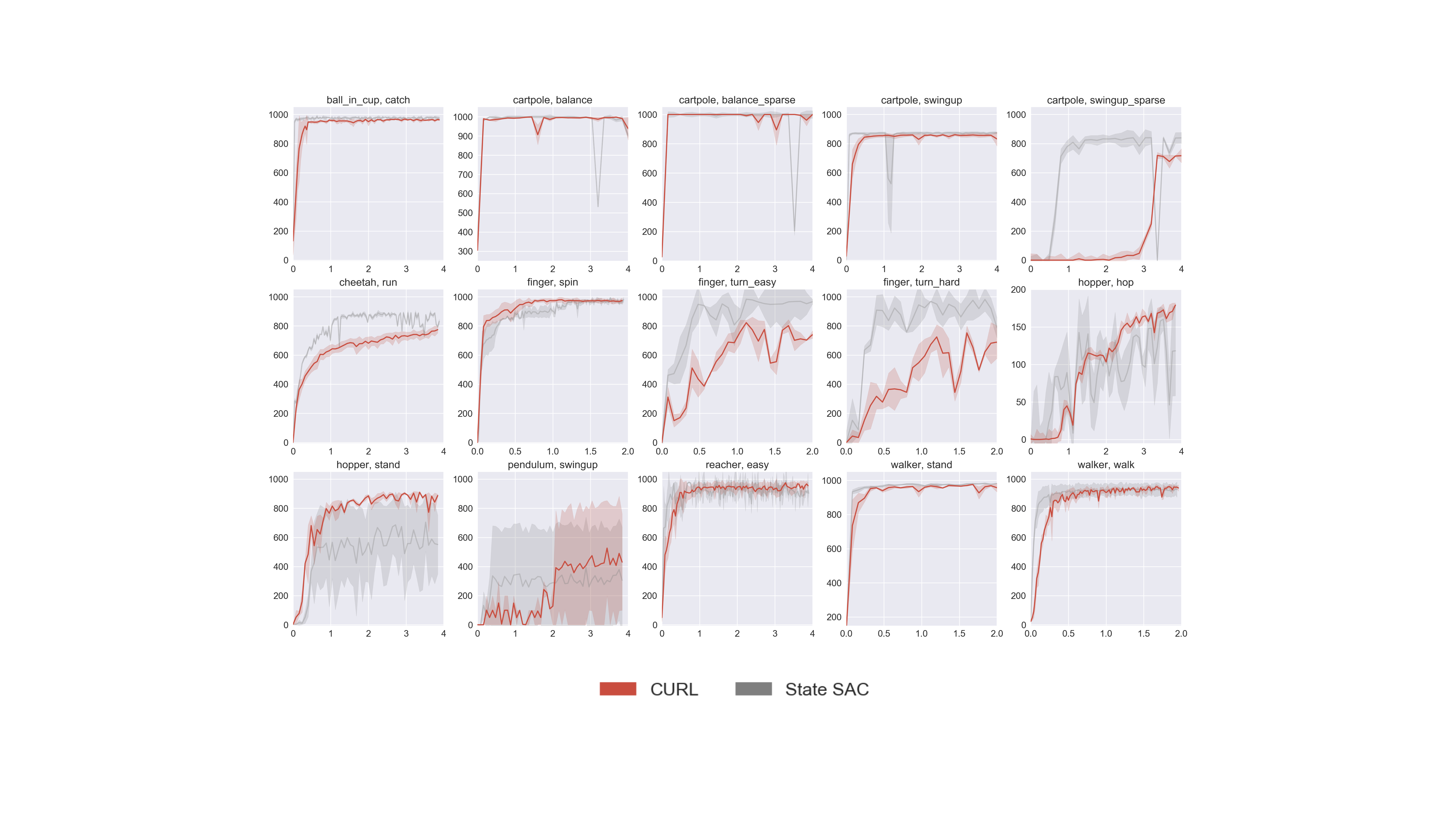
Can RL from pixels be as efficient as RL from state? – Robotics.ee
Reference line (RL) used to determine marginal bone level for the PS ...
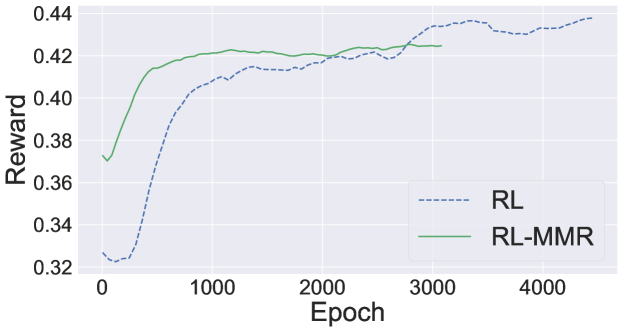
[2010.00117] Multi-document Summarization with Maximal Marginal ...
Interaction between RL agent with its environment in a typical RL ...
The standard RL model. Where at is the action taken by the agent at ...
State-value and policy representations in the deep RL agent and mouse ...
Can RL from pixels be as efficient as RL from state? - Robohub
shows the RL values that the RL Agent learned over time. As the ...
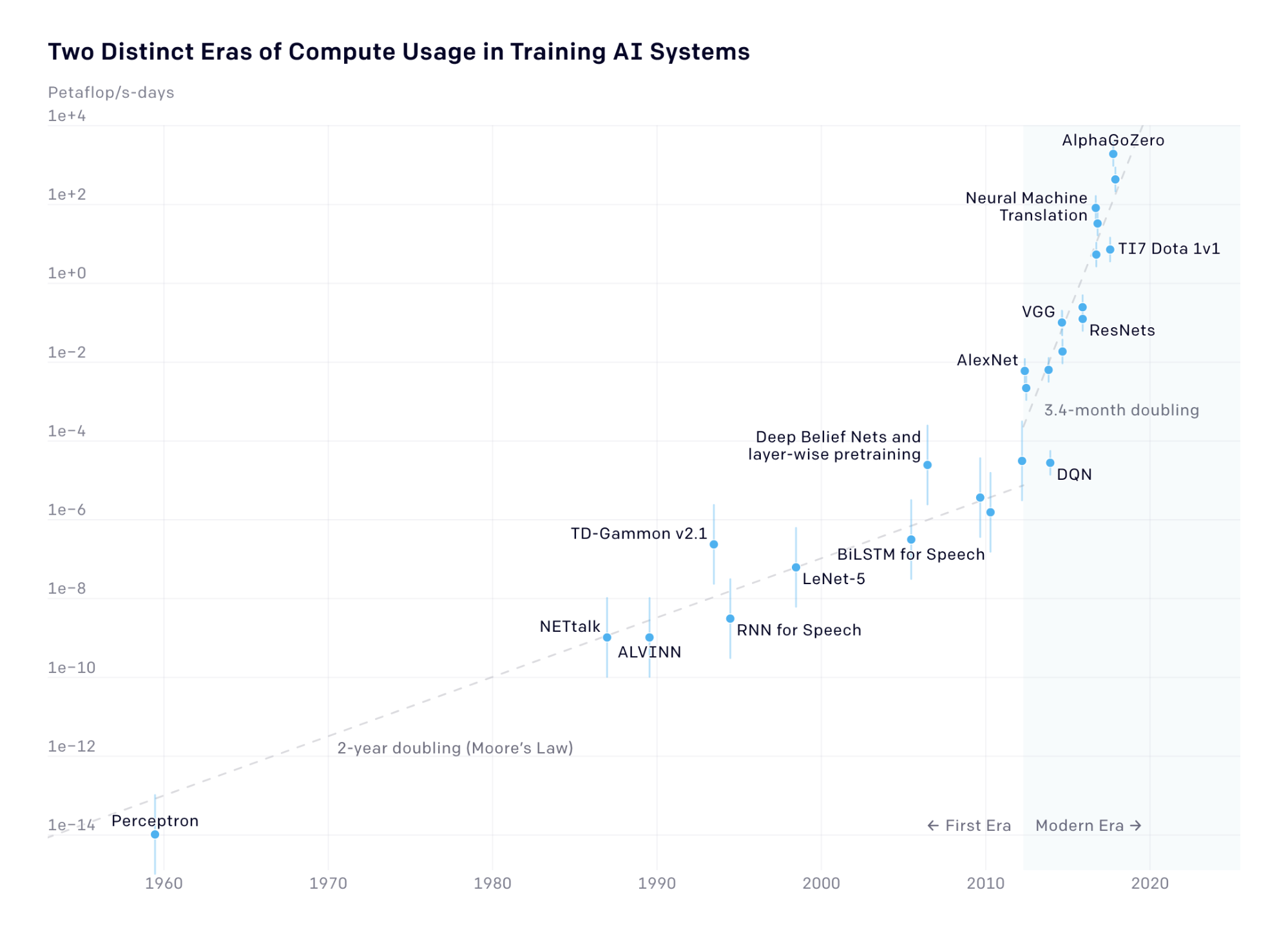
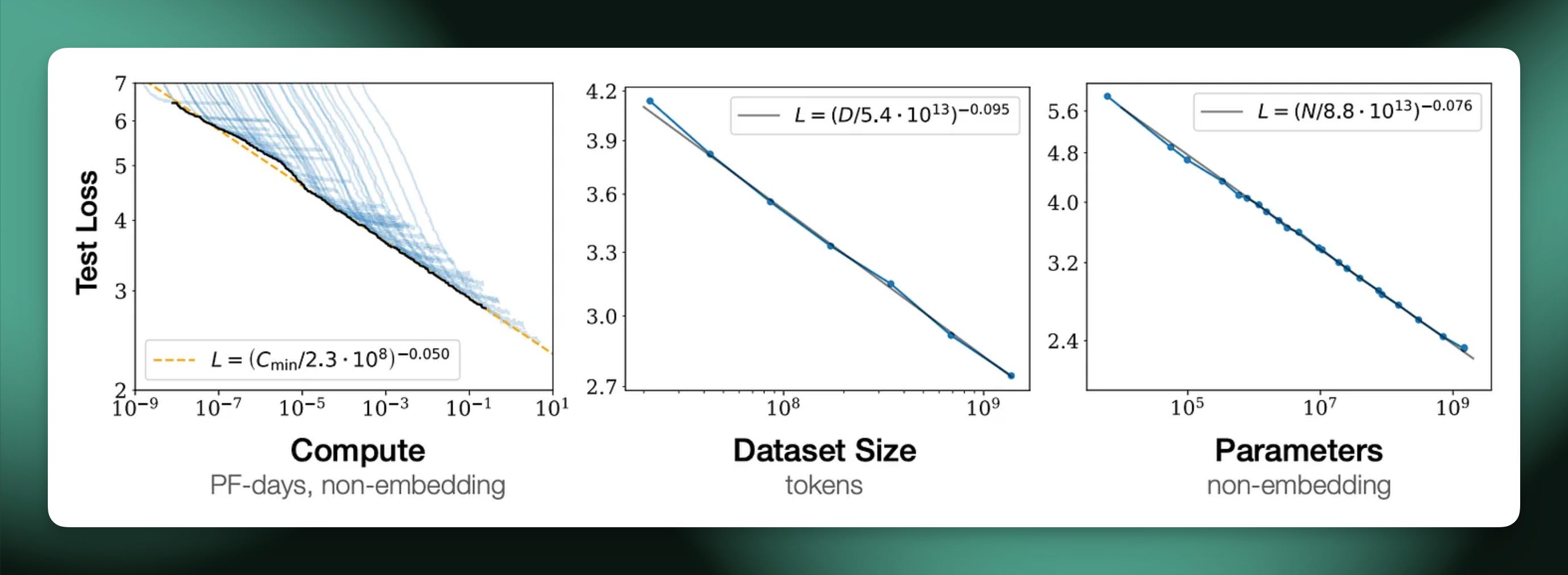
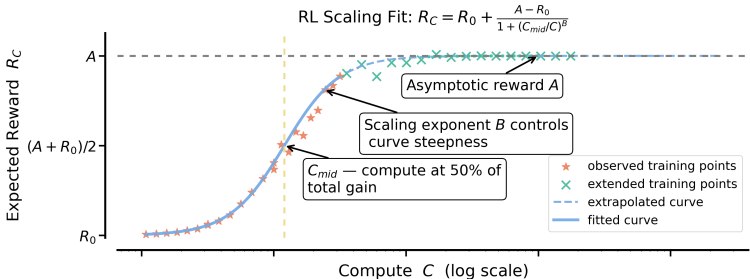
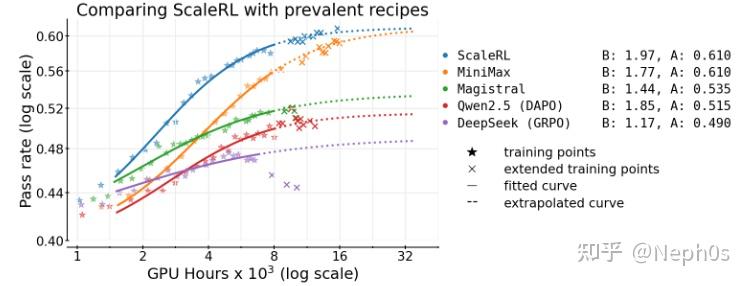
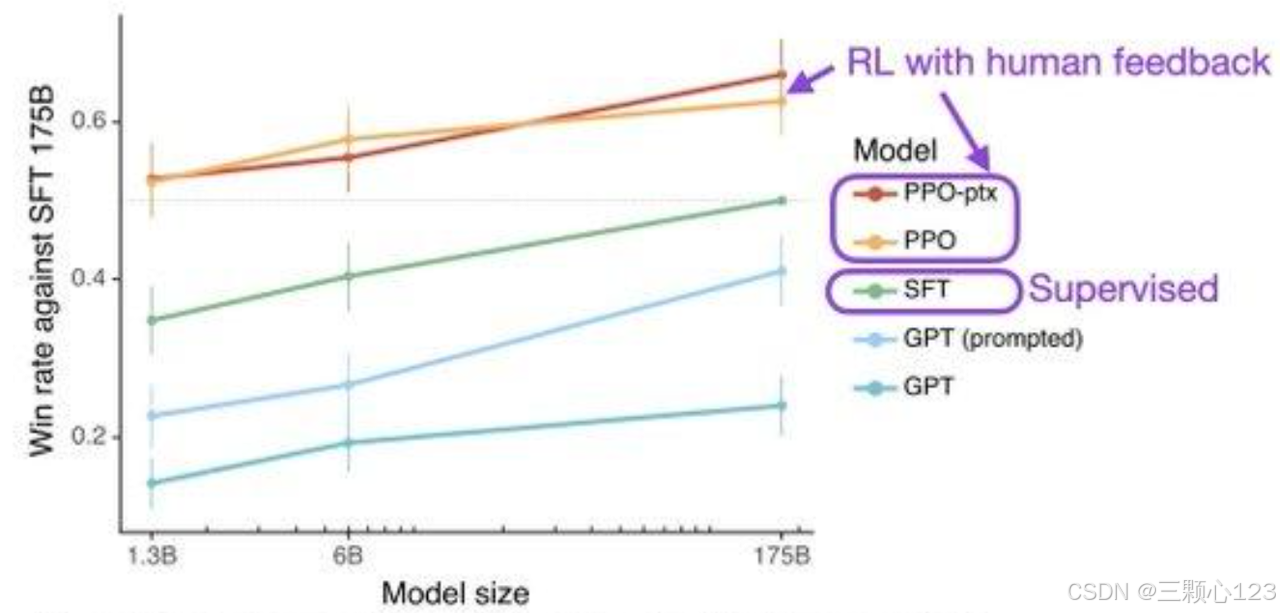
How to scale RL - by Nathan Lambert - Interconnects AI
RL average return with the real and simulated systems | Download ...
Overview of RL in ML. | Download Scientific Diagram
(State) : (Reinforcement Learning - RL) - . RL - S0 | PDF
The final RL policy, which is described by the optimal actions at each ...
What Does Line Status Marginal Mean at Bianca Wilson blog
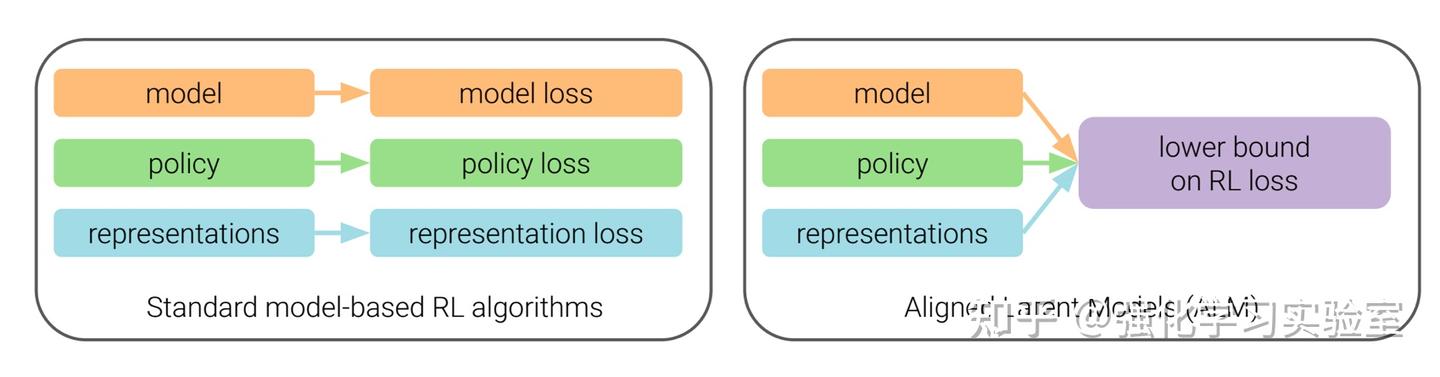
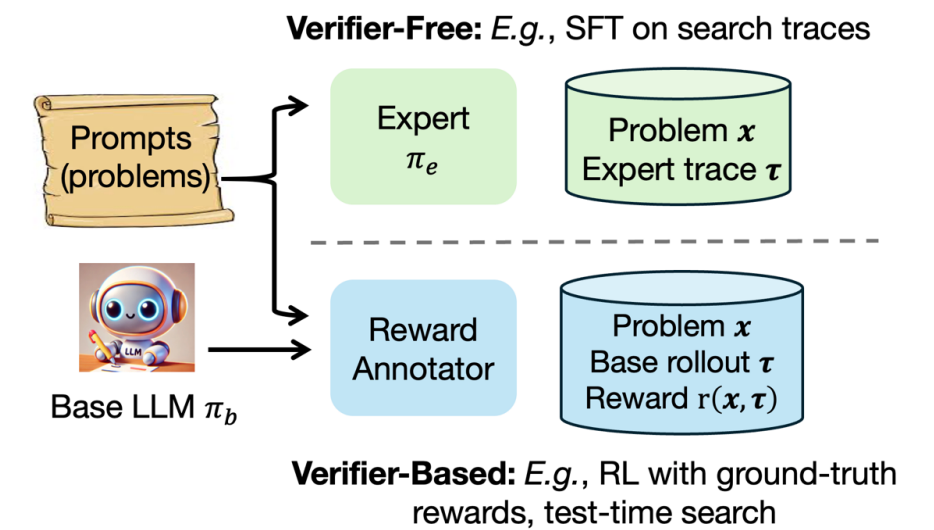
Making RL tractable by learning more informative reward functions ...
RL Agent Performance: The performance of the RL price-setting agent as ...
RL - Introduction to Reinforcement Learning | NIUHE
如何理解 LLM 中的 RL 算法? - 知乎
Reduced Level (RL): Methods to Calculate RL of a Point | Intermediate ...
论文分享:SIMPLIFYING MODEL-BASED RL - 知乎
【RL】Scaling RL Compute for LLMs | JustRL 1.5b_justrl: scaling 1.5b llm ...
Can RL from pixels be as efficient as RL from state? - ΑΙhub
LLM RL 2025论文(二)Logic-RL - 知乎
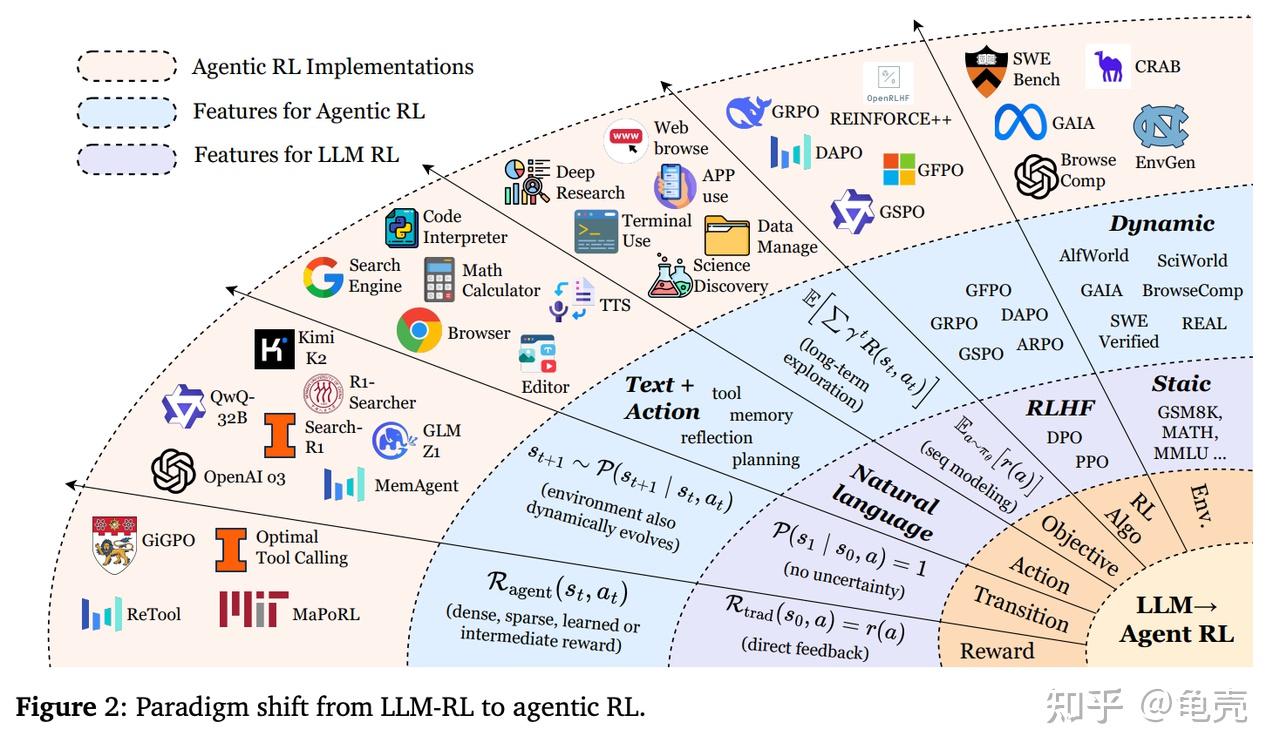
综述 | Agentic RL for LLM的最新进展与未来挑战,idea满满-CSDN博客
01. Basic of RL
RL 概念 + RL算法 | Simon Shi的小站
Pipeline of the proposed RL solution. | Download Scientific Diagram
The relationship between the minimum RL values with different ...
Estimated marginal means of SRL scores per week for AY 2020-2021 and AY ...
RL in VLA • Arthals' ink
Reduced Level (RL): Methods to Calculate RL of a Point
The structure of the RL agent. The control policy used online is shown ...
Parameters of the RL simulation. | Download Scientific Diagram
LLM RL 2025论文(三十二)MiniRL - 知乎
【论文解读】Agent RL Scaling Law:自发掌握工具以解决数学问题_agent rl scaling law ...
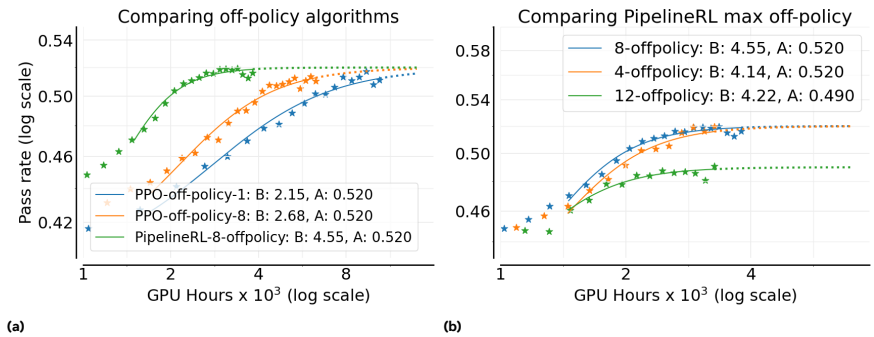
How to scale RL with compute:英伟达从ProRL到BroRL,多维度Scaling RL - 知乎
RL for LLM 综述整理 - 知乎
PPT - Kunstmatige Intelligentie / RuG PowerPoint Presentation, free ...
Basic components of RL. | Download Scientific Diagram
model based RL基础 - 知乎
Solved b) Determine the range of values of RL(RLmin and | Chegg.com
大模型RL的Scaling Law和最佳实践 - 知乎
Recent Advances in Reinforcement Learning for Continuous Control
半年RL没白学!终于把RL for LLM的本质说清了,零基础小白建议收藏!! - 知乎
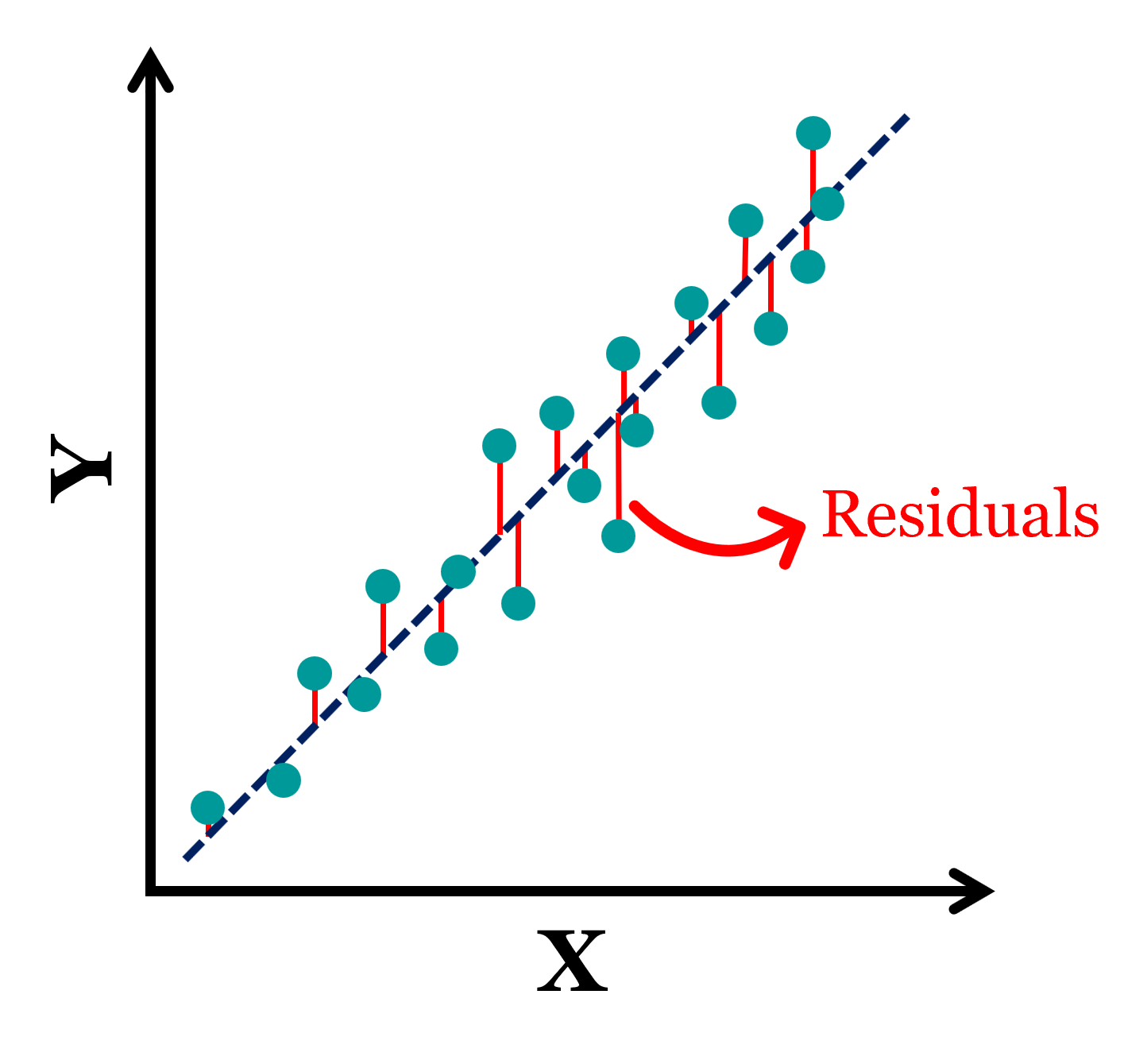
Schematic diagram of residual layer (RL) energy calculation. Red lines ...
rl-policy-gradient
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement ...
OpenAI一直推崇的突破Scale Law规律的训练方法-RL_rl中的动态采样原理和参数调整经验-CSDN博客
【RL-Fintech】RL for Market Making(0) - 知乎
RL学习笔记:RL中的探索与利用 - 知乎
RL相关知识补缺_rl model-CSDN博客
Access to only the reduced states {ρRλ} of some family of regions {Rλ ...
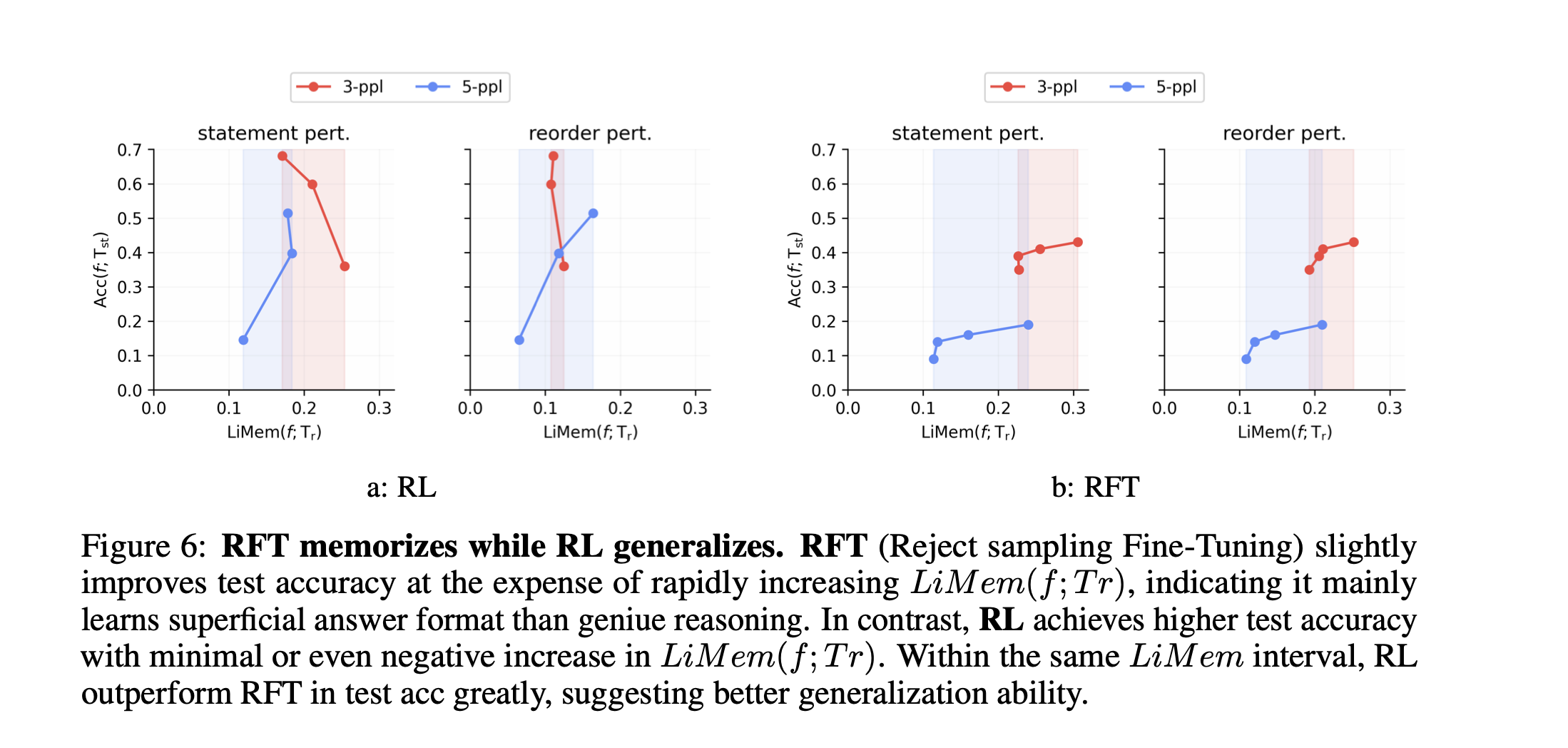
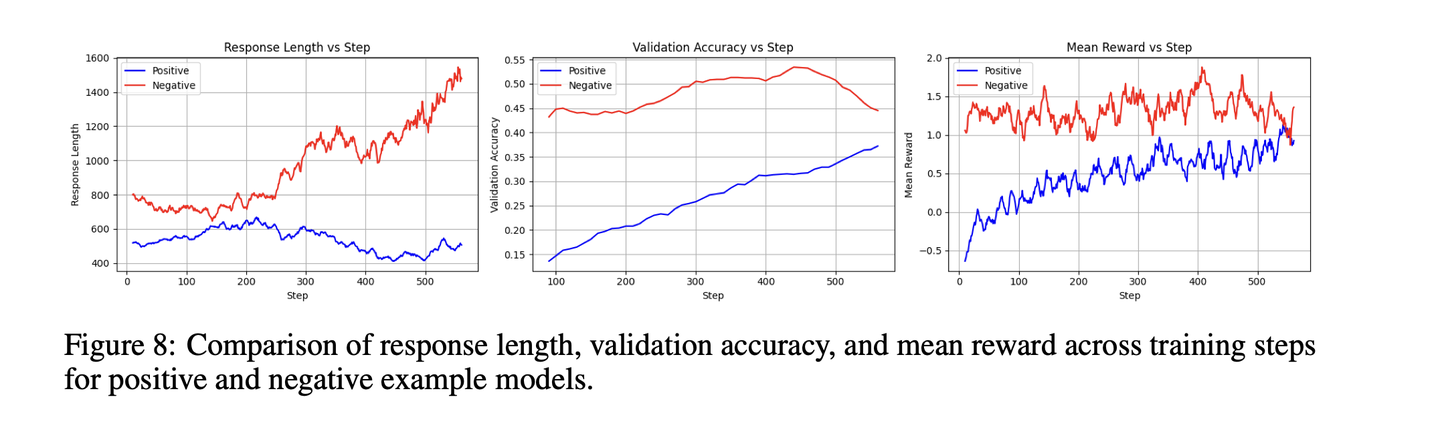
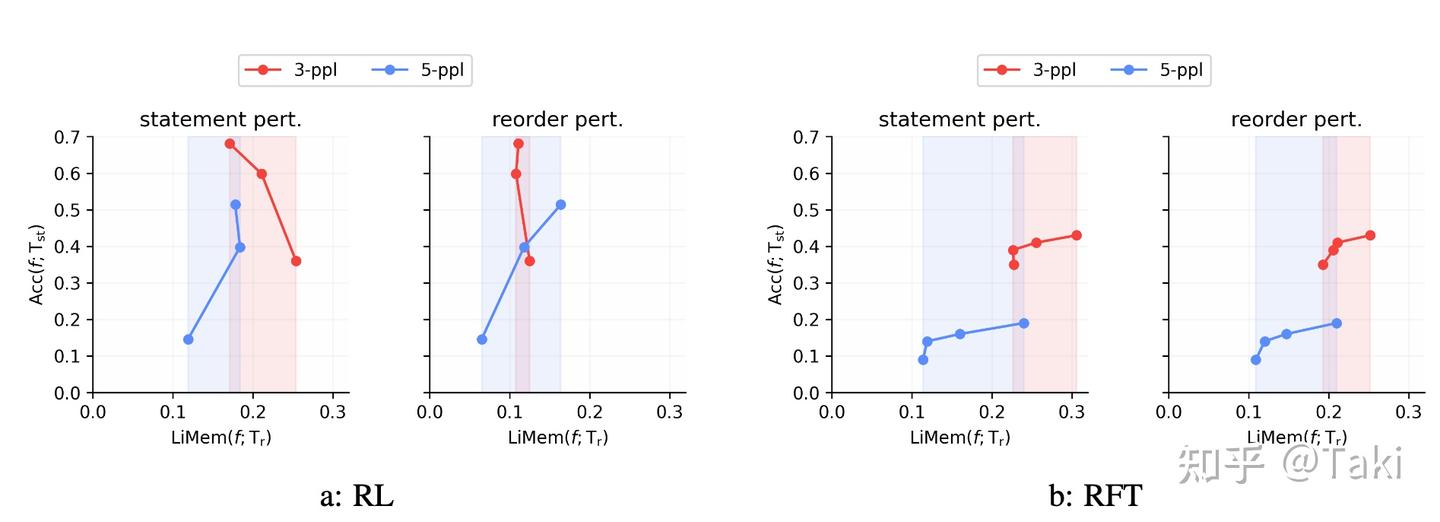
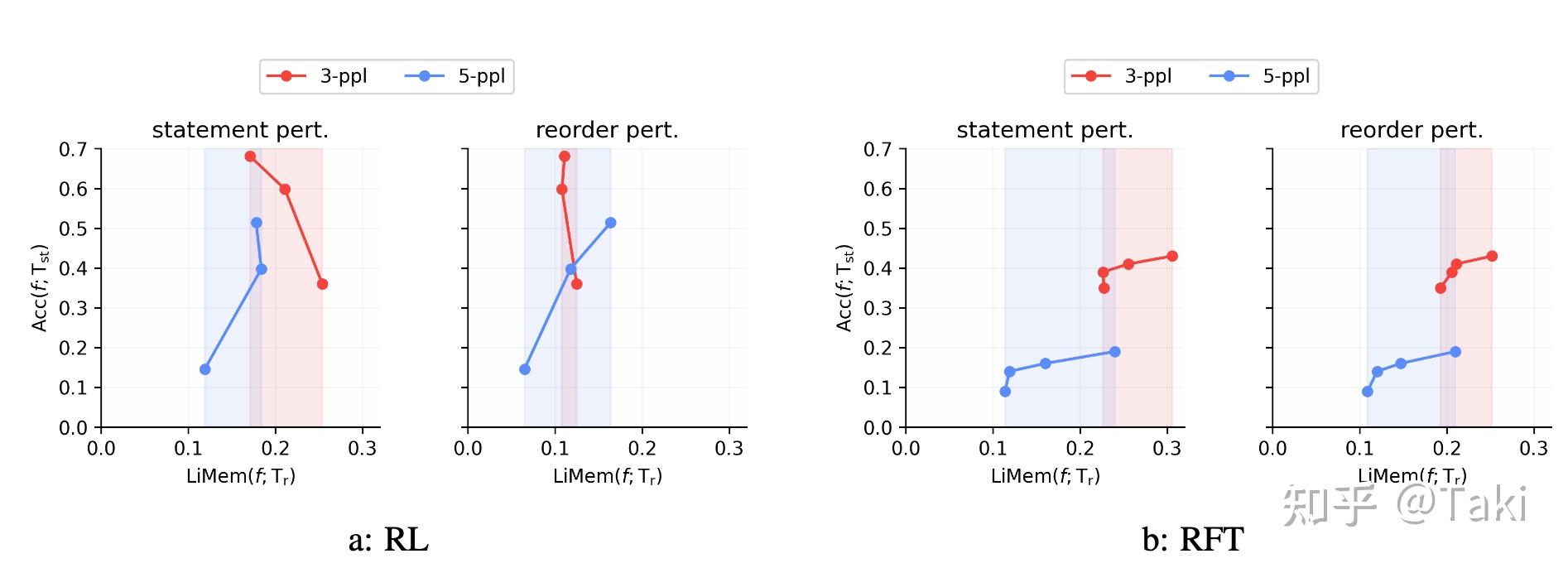
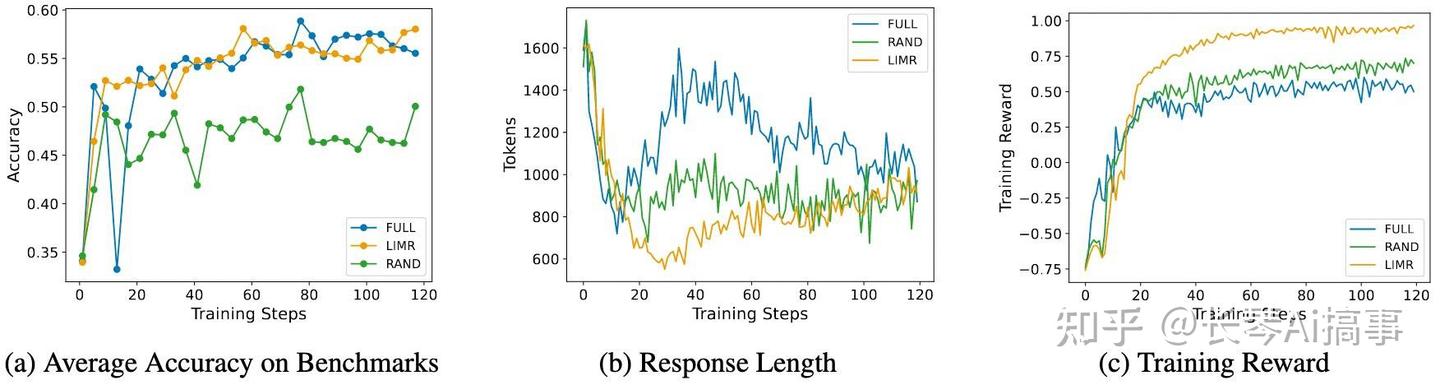
R1相关:RL数据选择与Scaling - 知乎
Imperial Japanese Navy Antisubmarine Escorts 1941-45 (New Vanguard, 248 ...
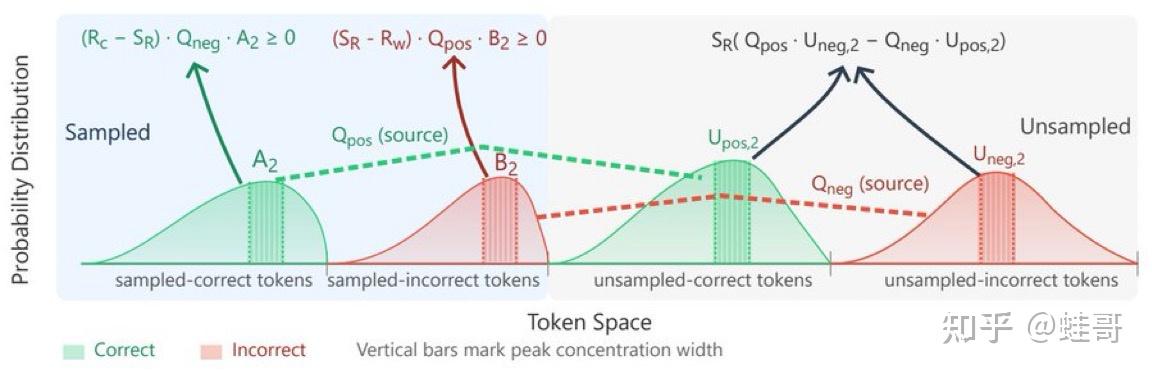
SPA: 把RL中的结果奖励归因成过程奖励 - 知乎
presentation